There are several MapReduce snippets to test and learn about Hadoop.
One of these samples is the reversed index, i.e. for each word we want to know which file it comes from. Thus the ouptut file should look like this:
hello test.txt
formation formation.txt test.txt
This example is mentioned on the Yahoo developer network, but it doesn’t work as is on version 0.20 of Hadoop.
We decided to rewrite parts of the code in order to make it compatible. This is what you will find in this blog article.
Note that for this article, I also looked at the code of this good blog article: http://marcellodesales.wordpress.com/2010/01/05/hadoop-0-20-1-api-refactoring-the-invertedline-cloudera-trainin-removing-deprecated-classes-jobconf/ .
Here is the complete java class InvertedExemple, together with the two jobs Map and Reduce :
1 | <br />package com.francelabs.hadoop.examples;<br /><br />import java.io.IOException;<br />import java.util.StringTokenizer;<br /><br />import org.apache.hadoop.conf.Configuration;<br />import org.apache.hadoop.fs.Path;<br />import org.apache.hadoop.io.IntWritable;<br />import org.apache.hadoop.io.LongWritable;<br />import org.apache.hadoop.io.Text;<br />import org.apache.hadoop.mapreduce.Job;<br />import org.apache.hadoop.mapreduce.Mapper;<br />import org.apache.hadoop.mapreduce.Reducer;<br />import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;<br />import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;<br />import org.apache.hadoop.util.GenericOptionsParser;<br />import org.apache.hadoop.mapreduce.lib.input.FileSplit;<br /><br />public class InvertedIndex {<br /><br /> public static class TokenizerMapper<br /> extends Mapper<LongWritable, Text, Text, Text>{<br /><br /> private Text word = new Text();<br /> private final static Text location = new Text();<br /><br /> public void map(LongWritable key, Text value, Context context<br /> ) throws IOException, InterruptedException {<br /><br /> String filename = ((FileSplit) context.getInputSplit()).getPath().getName();<br /> location.set(filename);<br /> StringTokenizer itr = new StringTokenizer(value.toString());<br /> while (itr.hasMoreTokens()) {<br /> word.set(itr.nextToken());<br /> context.write(word, location);<br /> }<br /> }<br /> }<br /><br /> public static class LineReducer<br /> extends Reducer<Text,Text,Text,Text> {<br /> private IntWritable result = new IntWritable();<br /><br /> public void reduce(Text key, Iterable values,<br /> Context context<br /> ) throws IOException, InterruptedException {<br /> StringBuilder valueBuilder = new StringBuilder();<br /><br /> for (Text val : values) {<br /> valueBuilder.append(val);<br /> valueBuilder.append(",");<br /> }<br /> //write the key and the adjusted value (removing the last comma)<br /> context.write(key, new Text(valueBuilder.substring(0, valueBuilder.length() - 1)));<br /> valueBuilder.setLength(0);<br /> }<br /> }<br /><br /> public static void main(String[] args) throws Exception {<br /> Configuration conf = new Configuration();<br /> String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();<br /> if (otherArgs.length != 2) {<br /> System.err.println("Usage: invertedindex ");<br /> System.exit(2);<br /> }<br /> Job job = new Job(conf, "inverted index");<br /> job.setJarByClass(InvertedIndex.class);<br /> job.setMapperClass(TokenizerMapper.class);<br /> job.setCombinerClass(LineReducer.class);<br /> job.setReducerClass(LineReducer.class);<br /> job.setOutputKeyClass(Text.class);<br /> job.setOutputValueClass(Text.class);<br /> FileInputFormat.addInputPath(job, new Path(otherArgs[0]));<br /> FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));<br /> System.exit(job.waitForCompletion(true) ? 0 : 1);<br /> }<br />}<br /> |
We will now compile the class :
• Create a folder to store the java classes :
1 | <br />% mkdir invertedindex_classes<br /> |
• Compile the java class :
1 | <br />% javac -classpath $HADOOP_HOME/hadoop-core-0.20.205.0.jar:$HADOOP_HOME /lib/commons-cli-1.2.jar -d invertedindex_classes InvertedIndex.java<br /> |
• Create a java Archive (JAR) to hold the executables :
1 | <br />% jar -cvf invertedindex.jar -C invertedindex_classes/ .<br /> |
• We then get a jar file: invertedindex.jar
Then we launch hadoop :
1 | <br />hadoop jar invertedindex.jar com.francelabs.hadoop.examples.InvertedIndex input newoutput<br /> |
We use as input some text files that are to placed in the input folder.
And the newoutput folder will be containing the output of our program. You should find in it a folder part0000 and a file SUCCESS :
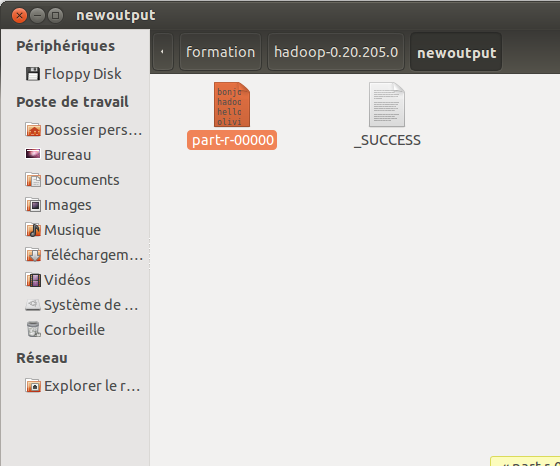
Inside the file part-r-00000, we have our reversed index :