In this tutorial, we will demonstrate how to do basic entity extraction in Datafari Community. This post is inspired from https://lucidworks.com/2013/06/27/poor-mans-entity-extraction-with-solr/
Note that for Datafari Enterprise, all the configuration is already done. You just need to add your custom rules in a specific UI, and for further advanced functionalities, Datafari Enterprise allows you to benefit from SolrTextTagger and 3rd party semantic entity extractors.
We want to extract 3 entities in our dataset (files from the Enron dataset in this example) :
- Persons
- Phone number
- If the document is a resume
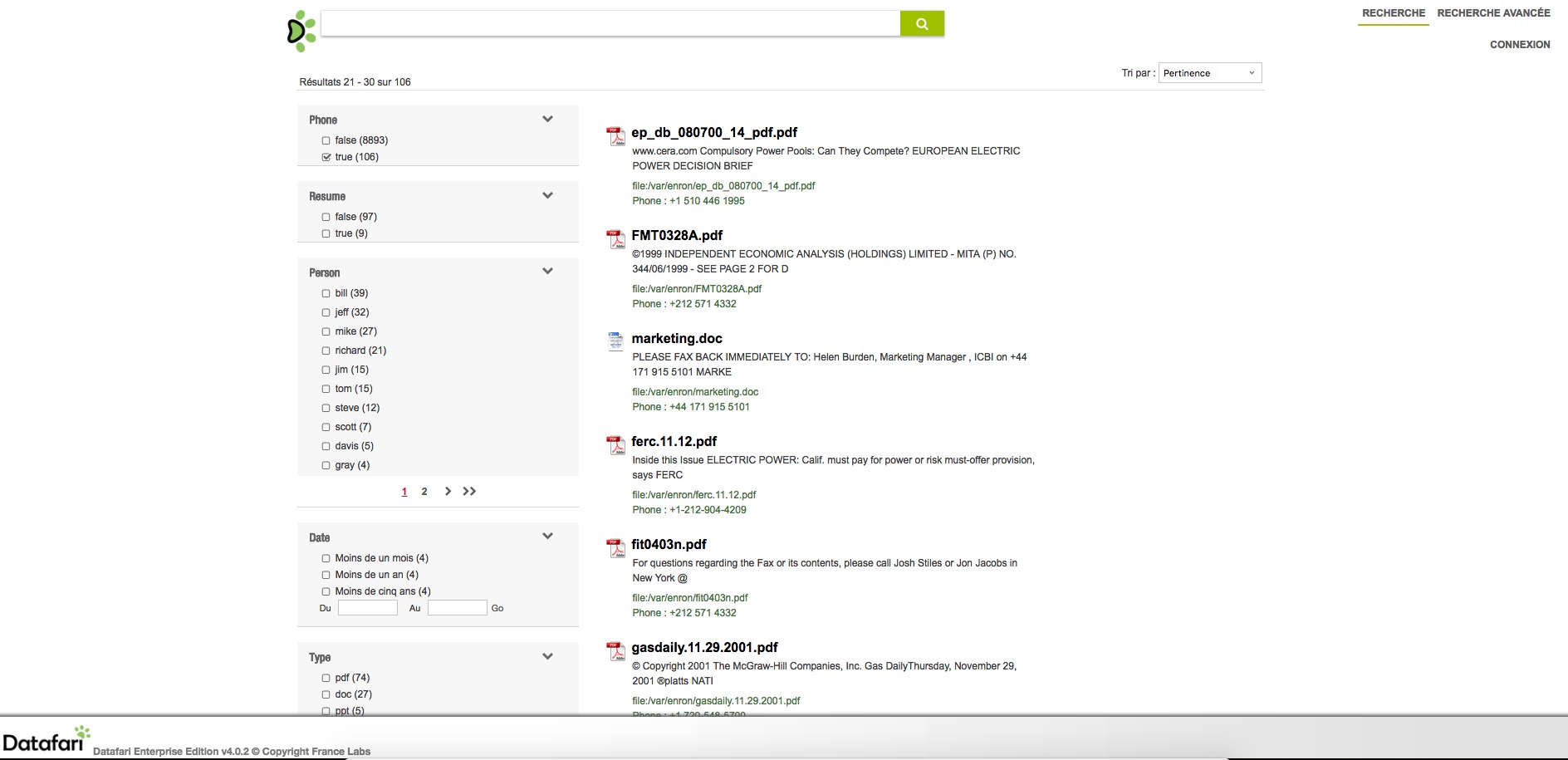
We want to have facets on it and display the phone number in the documents results list. A screenshot will be better to understand the final result so here it is :
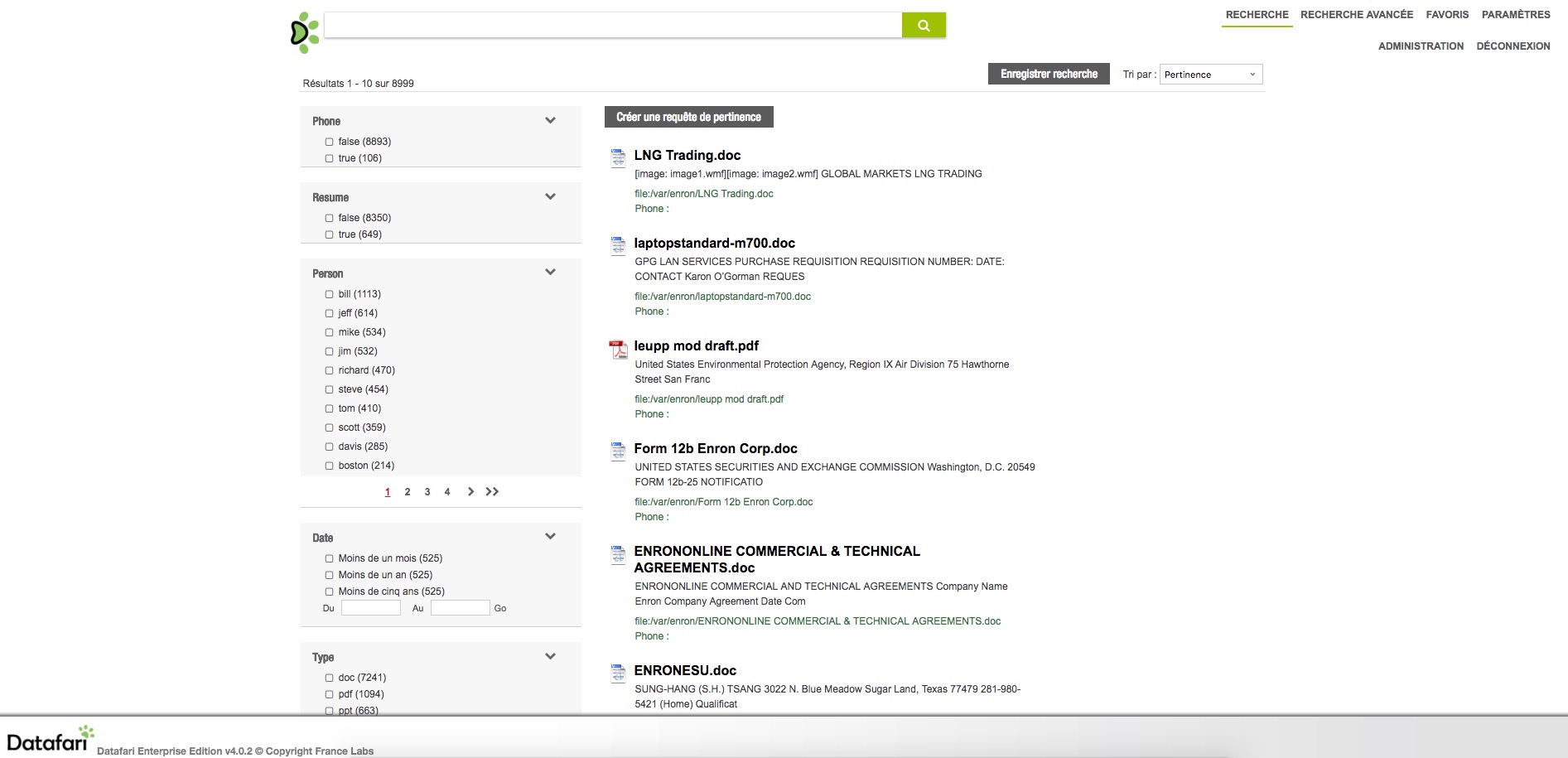 We will detail how to do that in the remainder of this post. Mostly by configuring Solr via its schema.xml. In addition, some coding in our custom update processor. Last, modifications of the front-end, with explanations on what to change in the AjaxFranceLabs framework.
We will detail how to do that in the remainder of this post. Mostly by configuring Solr via its schema.xml. In addition, some coding in our custom update processor. Last, modifications of the front-end, with explanations on what to change in the AjaxFranceLabs framework.
Let us begin with the Solr configuration.
Solr configuration
- Schema.xml
We need to add the Solr fields to store the entity extraction and do the facets we want. In our scenario, we want to display in the search interface the phone numbers, people names, but also a boolean value – used as facets- declaring the presence of at least on phone number or one name in a given document.
So we need 6 fields : entity_person, entity_person_present, entity_phone, entity_phone_present, entity_resume and entity_resume_present.
<field name="entity_person" type="key_phrases" indexed="true" stored="true" multiValued="true"/> <field name="entity_phone" type="string" indexed="true" stored="true" multiValued="true"/> <field name="entity_resume" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="entity_person_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_phone_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_resume_present" type="text_general" indexed="true" stored="true" multiValued="false"/>
Depending on what we want to do : faceting or not, we add for each entity extraction 2 fields : one for storing the data and another one to display or faceting the data itself or to tell to the user if this information is available or not.
For the entity person, in order to extract them in the content field, we will use a specific field type (key_phrases in the configuration below). It is a field containing any key phrases matching a provided list.
<fieldType name="key_phrases" class="solr.TextField" sortMissingLast="true" omitNorms="true"> <analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.ShingleFilterFactory" minShingleSize="2" maxShingleSize="5" outputUnigramsIfNoShingles="true" /> <filter class="solr.KeepWordFilterFactory" words="keep_phrases.txt" ignoreCase="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
Explanation from Lucidworks blog post :
“The field type analysis configuration uses a simple, whitespace, tokenizer; you may need to adjust this to suit your content. A shingle filter is used to group, in this case, 2 to 5 tokens into a single token (separated by a single space, by default). The maxShingleSize should be as large as the largest number of words in a single phrase. The “keep word” filter only passes through tokens that match the phrases in the keep_phrases.txt file.”
In our case the terms list is :
dix
richard
richard dix
gray
davis
gray davis
mike
tolstrip
mike tolstrip
ray hart
hart
Kyle Hoffman
kyle
hoffman
Richard Weingart
weingart
Bill Hutchings
bill
hutchings
STEVE MONTOVANO
steve
montovano
TOM CHAPMAN
tom
chapman
JIM STEFFES
jim
steffes
JANINE MIGDEN
janine
migden
JEFF DASOVICH
jeff
dasovich
ROY BOSTON
roy
boston
Susan Scott
Susan
scott
Latimer P. Lorenz
latimer
lorenz
Now that you have defined the fields, you need to push them to Zookeeper and reload the Solr collection (FileShare in Datafari).
To do that, edit the managed-schema file located in /opt/datafari/solr/solrcloud/FileShare/conf :
nano/opt/datafari/solr/solrcloud/FileShare/conf/managed-schema
Then add the fields after the fields that are already declared :
<field name="entity_person" type="key_phrases" indexed="true" stored="true" multiValued="true"/> <field name="entity_phone" type="string" indexed="true" stored="true" multiValued="true"/> <field name="entity_resume" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="entity_person_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_phone_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_resume_present" type="text_general" indexed="true" stored="true" multiValued="false"/>
Also add the fieldtype key_phrases :
<field name="entity_person" type="key_phrases" indexed="true" stored="true" multiValued="true"/> <field name="entity_phone" type="string" indexed="true" stored="true" multiValued="true"/> <field name="entity_resume" type="text_general" indexed="true" stored="true" multiValued="true"/> <field name="entity_person_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_phone_present" type="text_general" indexed="true" stored="true" multiValued="false"/> <field name="entity_resume_present" type="text_general" indexed="true" stored="true" multiValued="false"/>
Add the file keep_phrases.txt in /opt/datafari/solr/solrcloud/FileShare/conf with the content above.
Finally add a copyfield to copy the content field into the entity_person field.
<copyField source="content_*" dest="entity_person" />
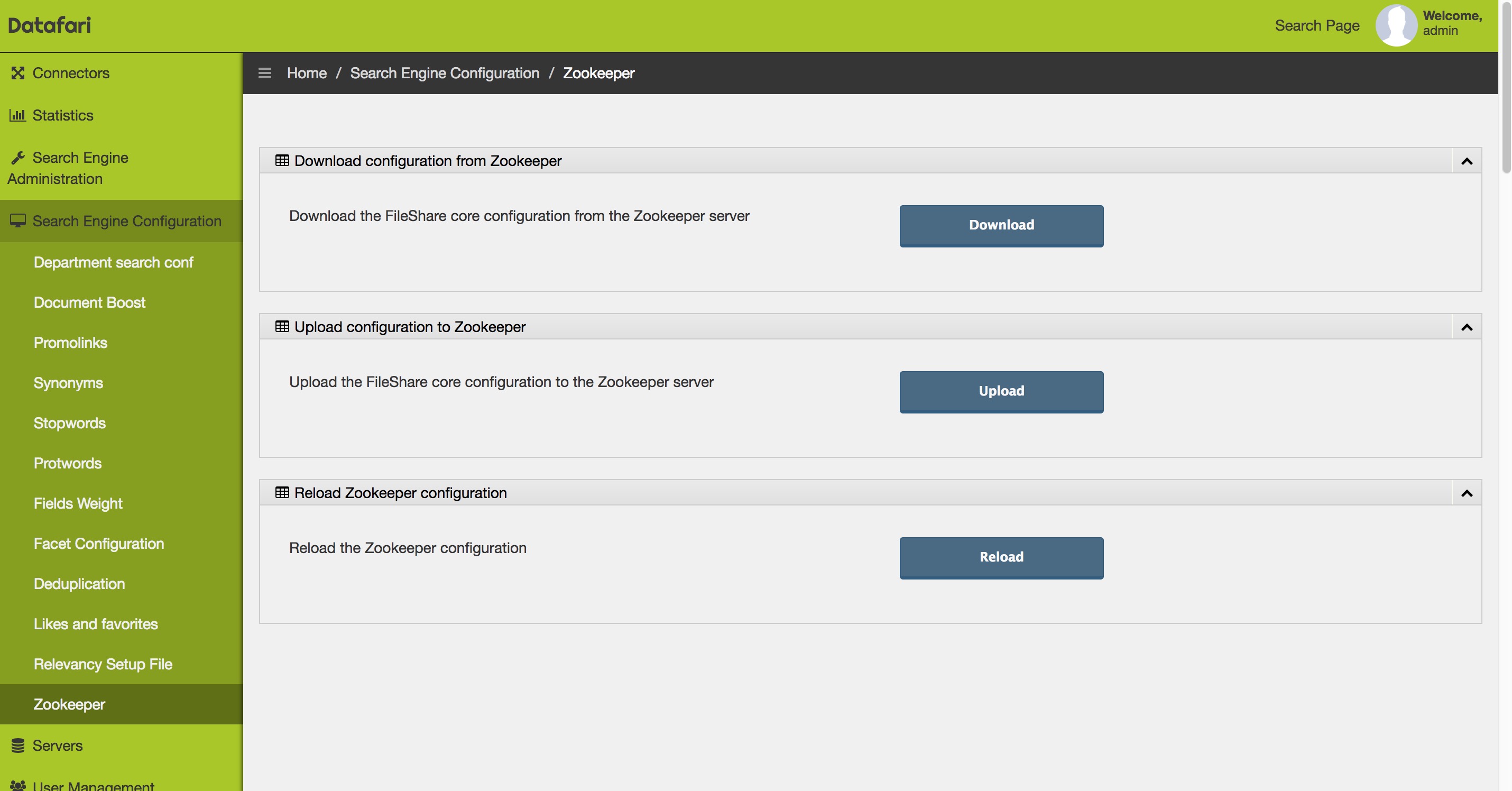
After that go to the Datafari admin UI and go to Search Engine Configuration -> Zookeeper.
Then click on the Upload button in the Upload configuration to Zookeeper. Then click on the Reload button in the Reload Zookeeper configuration
It is time to add some Java code in the custom update processor that we already have in Datafari to fill the other entities.
We use regex rules for this purpose :
- For phone numbers we use a common regex rule for US phone
- For resumes, we apply a basic rule : if the content field contains the word resume, then we consider that the entity resume is present for this document (yes, it is very basic, but valid for the sake of this demo).
Basically we get the content of the content field and we check if one of the patterns match. If yes then we flag the document that contains the entity and we store the entity in a specific field.
Add the following code in the DatafariUpdateProcessor Java class in /datafari-updateprocessor/src/main/java/com/francelabs/datafari/updateprocessor/DatafariUpdateProcessor.java, within the processAdd method :
/*
* Entity Extraction Part 1
* /
String phone;
String content="";
final SolrInputField contentFieldFr = doc.get("content_fr");
final SolrInputField contentFieldEn = doc.get("content_en");
if (contentFieldFr != null){
content = (String) contentFieldFr.getFirstValue();
}
else if (contentFieldEn != null){
content = (String) contentFieldEn.getFirstValue();
}
/*
* Entity extraction part 2
* /
final Pattern pattern_phone = Pattern.compile("\\(?\\+[0-9]{1,3}\\)? ?-?[0-9]{1,3} ?-?[0-9]{3,5} ?-?[0-9]{4}( ?-?[0-9]{3})? ?(\\w{1,10}\\s?\\d{1,6})?");
final Matcher matcher_phone = pattern_phone.matcher(content);
if (matcher_phone.find()) {
phone = matcher_phone.group();
doc.addField("entity_phone", phone);
doc.addField("entity_phone_present", "true");
}
else {
doc.addField("entity_phone_present", "false");
}
final Pattern pattern_resume = Pattern.compile(".*resume*");
final Matcher matcher_resume = pattern_resume.matcher(content);
if (matcher_resume.find()) {
doc.addField("entity_resume_present", "true");
}
else {
doc.addField("entity_resume_present", "false");
}
final SolrInputField entityPersonField = doc.get("entity_person");
if (entityPersonField != null){
if (doc.getFieldValues("entity_person").size() > 1) {
doc.addField("entity_person_present", "true");
}
}
else {
doc.addField("entity_person_present", "false");
}
Then build the project and replace the existing JAR in your Datafari instance by the new one in /opt/datafari/solr/solrcloud/FileShare/lib/custom/datafari-updateprocessor-4.0.2-Community.jar.
Now you can configure the UI.
To know how to add facets to the UI, go to this page : https://datafari.atlassian.net/wiki/spaces/DATAFARI/pages/6651920/Manually+adding+facets+to+the+Datafari+UI.
In this example, we add the facets entity_phone_present (yes/no), entity_person (we display the different terms) and finally the facet entity_resume_present (yes/no).
If you want to display the field entity_phone below the link section of the document by example, you can add it in SubClassResult.widget.js located in /opt/datafari/tomcat/webapps/Datafari/js/AjaxFranceLabs/widgets
Then add the following lines :
var phone ="";
if (doc.entity_phone != undefined){
phone = doc.entity_phone;
}
elm.find('.doc:last .address').append('<br/><span>Phone : ' + phone+ '</span>');
Finally launch the indexation in ManifolCF UI and voilà ! You can see in the Datafari UI your new entities.